The internet has lots of servers…
Every time you open your browser, it’s constantly communicating with servers all across the globe, pulling in their information to display on your screen. Servers are just a term for computers running a specific set of software which allows them to talk to your browser. We’ll look at how exactly this communication happens and why it matters.
Any computer can become a server if you installed this software on it – which is exactly what you’re doing when you install MAMP or WAMP, which includes the popular Apache server software.
How computers talk to each other over the internet
All servers do is serve streams of text characters to your browser. Yes, behind the scenes your browser is talking to other computers in English (mostly). When the internet was first devised, Tim Berners-Lee and his team at CERN created the first version of the HTTP (Hypertext Transfer Protocol) which is accepted today as the most common convention for how computers communicate over the internet. Back in the day, it had exactly one command “GET” which, as you’d imagine, would retrieve a stream of html text from the server and display it on the screen.
To this day, most computers on the internet are still using this format to request pages from servers. Billions, or even trillions, of “GET”s are sent every day, and trillions of servers are answering “OK” in response.
What’s in a URL?
Lets have a look at what’s happening when you type the following in your browser’s address bar:
http://www.bbc.com/news/science_and_environment
Your browser dissects it into the following pieces:
- http:// – This is the protocol we’re going to use. As you may have noticed, http gets used A LOT. Nowadays, https is taking over. It’s an encrypted form of http which is more secure.
- www.bbc.com – This the server we’d like to talk to. There’s an entire infrastructure on the internet to look up these words and translate them into a machine readable IP address (for example, bbc.com resolves to 151.101.36.81 which is the unique address of one of the servers that is run by the BBC).
- /news/science_and_environment – This is the page we’d like on the server. It gets sent to the server in the HTTP request so that it can look up that specific page for us.
We can actually send the HTTP request ourselves without even having to use a browser. If you have access to a Mac or Linux machine, open a terminal and type:
telnet www.bbc.com 80
The telnet program should tell you it’s connected:
"Trying 151.101.36.81... Connected to bbc.map.fastly.net. Escape character is '^]'."
Now you’re free to send an HTTP request. Let’s get the /news/science_and_environment page. Type the following two lines, pressing enter after each one:
GET /news/science_and_environment HTTP/1.1 Host: www.bbc.com
Press ‘enter’ twice after the last line to tell the server you’ve finished your request. Note that any character you type gets sent immediately to the server, so if you mistype, you can’t backspace! It may be easier to copy and paste the lines directly into your terminal, depending on how quick your typing skills are.
If you did it correctly, the server should respond with a whole stream of data, lines and codes. Right at the top of the response you should see:
HTTP/1.1 200 OK
Lets take a closer look at this line for a minute, as it’s the most important.
- The server is letting us know that it acknowledges that we want to use HTTP version 1.1, and it agrees and will also use HTTP version 1.1 to respond.
- It’s given us a “200 OK” status code. This is a three digit code which lets us know the success or failure of the command at a single glance. Some of the more familiar ones you may have seen around the internet are:
- 404 – Not Found
- 301 – Moved Permanently (this will instruct your browser to redirect to a URL of the servers choice)
- 403 – Forbidden (The request was valid, but the server refused to respond to it. It could be that you are not logged in, or don’t have necessary permission to view the page)
- 503 – Service Unavailable (The server is currently unavailable because it is overloaded or down for maintenance)
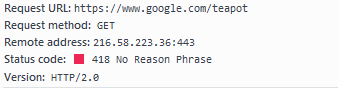
Never let it be said that computer scientists don’t have a sense of humour. In 1998 an ‘official april fools’ code was added to the protocol: “418 – I’m a Teapot”. This was designed to be used by the Hyper Text Coffee Pot Control Protocol, and is expect to be returned by automated teapots if they are ever asked to brew coffee. If you go to www.google.com/teapot, you’ll recieve a 418 error:
Back to the server’s response. Following the status line is a whole bunch of key-value pairs printed line-by-line:
Server: Apache Content-Type: text/html Expires: Wed, 30 Nov 2016 08:26:25 GMT Content-Language: en Etag: "b6aac6bb639382be0c3562b9aa5a7c96" Content-Length: 212326 Accept-Ranges: bytes Date: Wed, 30 Nov 2016 08:25:25 GMT Connection: keep-alive Set-Cookie: BBC-UID=3f2cebf576f507ef047380c9bc7d0866f9d33ecf12542f9d18141c9cddbfb32a0; expires=Sun, 29 Nov 2020 08:25:25 GMT; path=/; domain=.bbc.com Cache-Control: private, max-age=60 Vary: Accept-Encoding
These are known as Headers, and you’ll notice that you actually sent one of your own with the request. HTTP Headers are very useful, and when they come back from the server they will let your browser know information about the page, like how many bytes long it is, what language it’s in and how it’s encoded. They also instruct the browser to do things like redirect you to a different URL, store a cookie on your computer, cache this webpage for future use, and so on.
Some interesting things we can see happening in our request:
- The BBC server reports that it’s running Apache server software.
- The BBC server is requesting that our browser store a cookie for it (the Set-Cookie header). This cookie is very long-term and should only expire 4 years from now. It’s only valid for the bbc.com server and any pages on that server. From now on, the browser will send this cookie through back to BBC’s server with any new HTTP GET command if we ask for more pages from bbc.com.
- The content of this page is set to expire in 1 minute. So the browser now knows that it can cache this website and store it for future use. If the user refreshes the page less than a minute later, the browser can safely assume that the server will not have changed the page since then. (This is a loose guideline and the browser doesn’t have to respect this.)
Your browser is also free to send Headers with the GET request. Your browser can let the server know that it has cookies stored from the last time it visited, or that it has the ability to compress and uncompress the data so the server can send back the response in a ZIP compressed format and it will understand how to decode that.
Now what?
Now that the browser has received the page from the server, it will start to decode and read the contents. This means uncompressing or decrypting it if necessary, and then running through the HTML and building up a visual representation of the page on the screen (known as the DOM). Every time the browser encounters a reference to an image file, CSS stylesheet or Javascript file, it will send out more HTTP GET requests to retrieve those. They in turn can have even more references to other files inside them, so those have to be fetched as well. Now you can see why most web developers try to compress and gather all their Javascript files into a single monolithic file, or compile their CSS into a master stylesheet. Each of those HTTP requests can take a while to establish (resolving the domain, sending the request, establishing a secure connection, decrypting the response, etc.) so it’s in everyone’s best interest to keep the number of HTTP requests needed to load your page down to a minimum.
Okay so what is this good for?
Well, knowing how this major piece of the internet operates is the first step in becoming a web developer or even just a well-informed web citizen. Plus, if you develop websites for a living, you are going to need to analyse and understand HTTP responses so that you can tell what’s going on when stuff breaks. Today’s decent browsers all have developer tools built in (usually accessed with F12) that you should already be using. These let you see the individual HTTP requests being made at a glance:
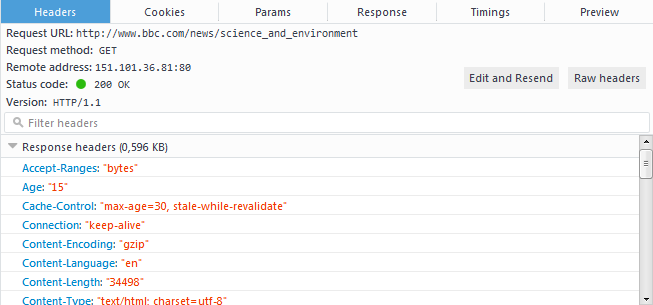
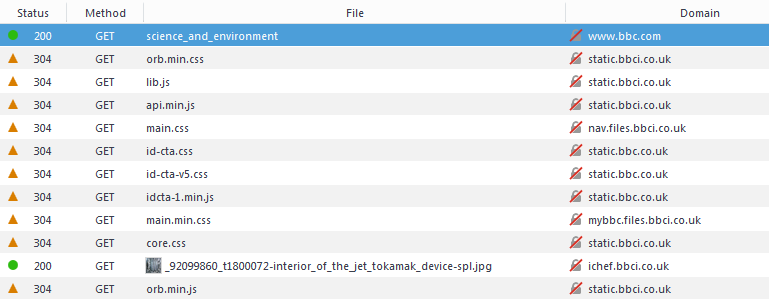
This is a screen from Firefox’s Developer Tools, specifically the “Network” tab. It’s showing the initial HTTP request we made to load /news/science_and_technology. You’ll see it’s indicating a status of 200 OK for that initial request, and showing all the headers received back from the server.
Below that, you’ll notice all the further stylesheets and javascript files which the page has references to, so those are loaded next. I had already visited this page not long ago, so they have statuses of 304 which means “Not modified since the last time you downloaded this file.” and instructs the web browser that according to the server, the version of the file the browser has in cache is good enough to use for now.
Wrapping Up
So we saw how browsers and servers communicate using pretty much plain English most of the time, and that this is almost never seen by any human eyes! This is communication over the internet in its most basic form. As the net has evolved, new layers of features and complexity have been added on top of good old HTTP. Nowadays most HTTP traffic is encrypted using HTTP over SSL, more commonly known as HTTPS. The next version of the protocol, HTTP/2 has already been developed, and addresses many of the shortcomings of the first version. However it’s never easy to shift an entire internet over to a new protocol overnight.
Thankfully that means our newly gained knowledge of the HTTP protocol will still be valid for some time to come.